Разбираем Oh-My-Pi: как новая архитектура Agent Harness решает проблемы Claude Code
Выясняем, что такое agent harness. Разбираем изнанку современных ИИ-агентов, архитектурный тупик привычных CLI-агентов и новый опенсорс-проект Oh-My-Pi, по сути полноценную IDE с интеграцией языковых серверов LSP и runtime-отладки DAP.

Каждый раз, когда вы запускаете Claude Code, создается ощущение, что вы общаетесь с языковой моделью напрямую. Но это не так. Между разработчиком и нейросетью всегда есть прослойка, которую называют agent harness (обвязка агента).
Новый опенсорс-проект Oh-My-Pi (или коротко — OMP) наглядно демонстрирует, что обвязка большинства привычных CLI-ассистентов устроена далеко не так эффективно, как могла бы. Давайте разберем четыре архитектурных решения в Oh-My-Pi, которые устраняют ключевые ограничения Claude Code.
Что такое agent harness?
Представьте, что LLM — это конь-тяжеловоз. Ваша кодовая база — тяжелый груз, который нужно доставить из точки А в точку Б. Обвязка (harness) — это упряжь. Без неё сдвинуть этот груз с места не получится.
Этот образ здесь максимально точен. ИИ-агент не просто читает код — он трансформирует его под конкретную задачу и выдает готовый результат в виде рабочего продукта.
По сути, обвязка состоит из четырех элементов:
- Контекст: файлы вашего проекта и история чата.
- Модель: сама нейросеть.
- Правила и промпты: инструкции из файлов вроде
CLAUDE.mdилиAGENTS.md. - Инструменты: действия, которые агент может выполнять в системе.
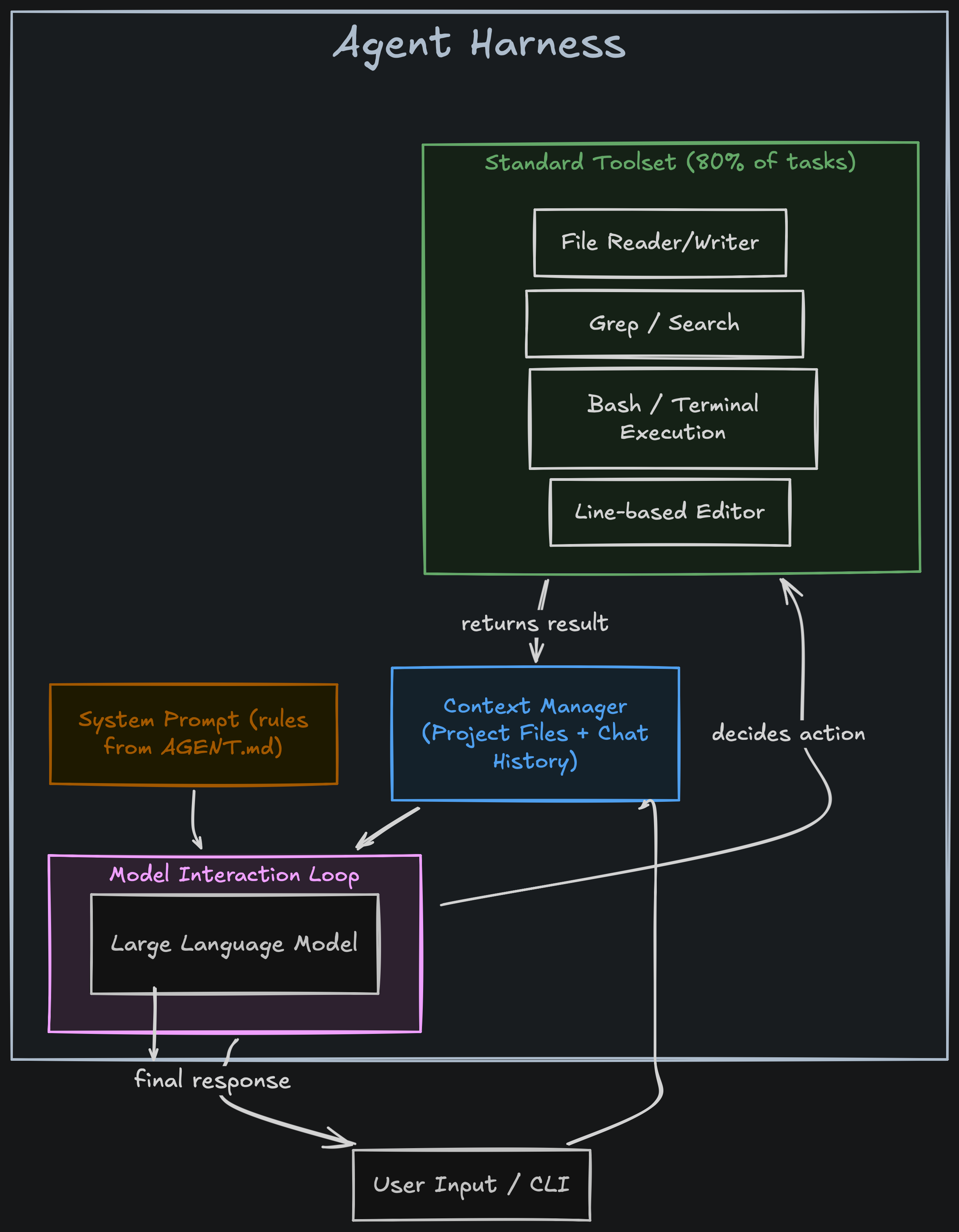
На практике около 80% задач решаются базовым набором действий: прочитать файл, найти строку через утилиту поиска, изменить ее или выполнить команду в терминале. Примерно так устроен любой ИИ-помощник.
Но для большинства популярных CLI-агентов ваш проект — это не приложение со сложной архитектурой, а просто папка с набором текстовых файлов. Они воспринимают код как обычный текст, а не как логическую структуру. Разработчики OMP решили эту проблему, внедрив в свою обвязку инструменты полноценной среды разработки.
1. Поддержка Language Server Protocol (LSP)
LSP — это стандарт, по которому современные среды разработки (вроде VS Code) взаимодействуют с языковыми серверами конкретного языка программирования для семантического анализа кода.
OMP подключается к языковому серверу проекта напрямую — например, к rust-analyzer, pylsp или gopls. Благодаря этому рефакторинг идет на уровне семантики, а не простых символов. Модель видит связи между файлами и изменяет код атомарно. Стандартный CLI-агент превращается из простого инструмента текстового поиска и редактора строк в полноценную среду разработки.

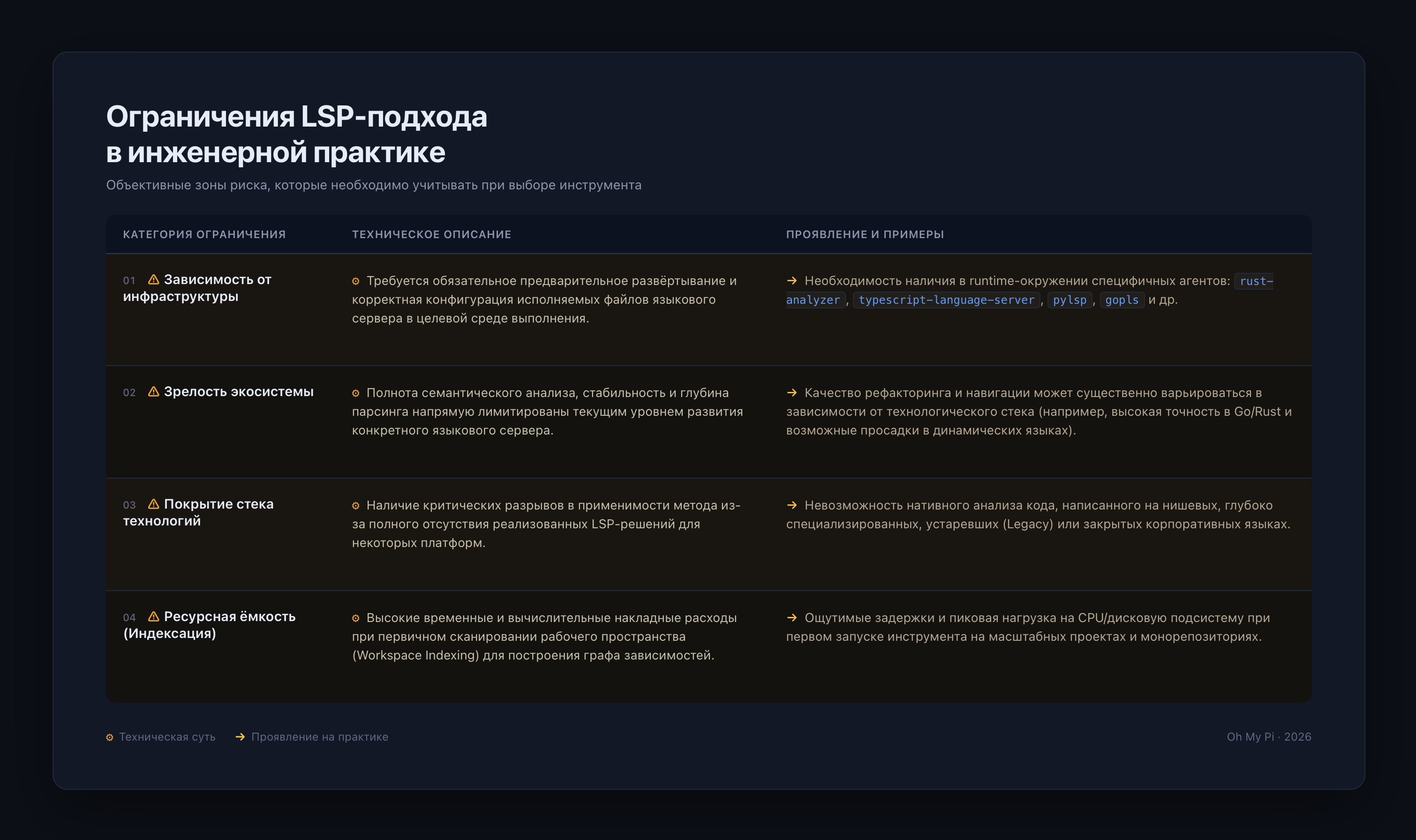
Однако есть ограничения:
- LSP-сервер должен быть установлен и доступен в окружении проекта.
- Качество рефакторинга напрямую зависит от возможностей LSP-сервера для конкретного языка (для некоторых языков их просто не существует).
- Индексация крупного рабочего пространства на холодную может занять достаточно много времени.
2. Интеграция с отладчиками через DAP (Debug Adapter Protocol)
Обычный CLI-ассистент бессилен, когда нужно разобраться в поведении кода во время выполнения. Например, если завис Go-сервис, простой вывод через print не покажет состояние горутин. Или когда вы пытаетесь отловить состояние гонки (race condition) в асинхронном коде Python — стандартный помощник не может заглянуть внутрь процесса. Бывает и так, что ошибка исчезает без видимых причин сразу после добавления логирования.
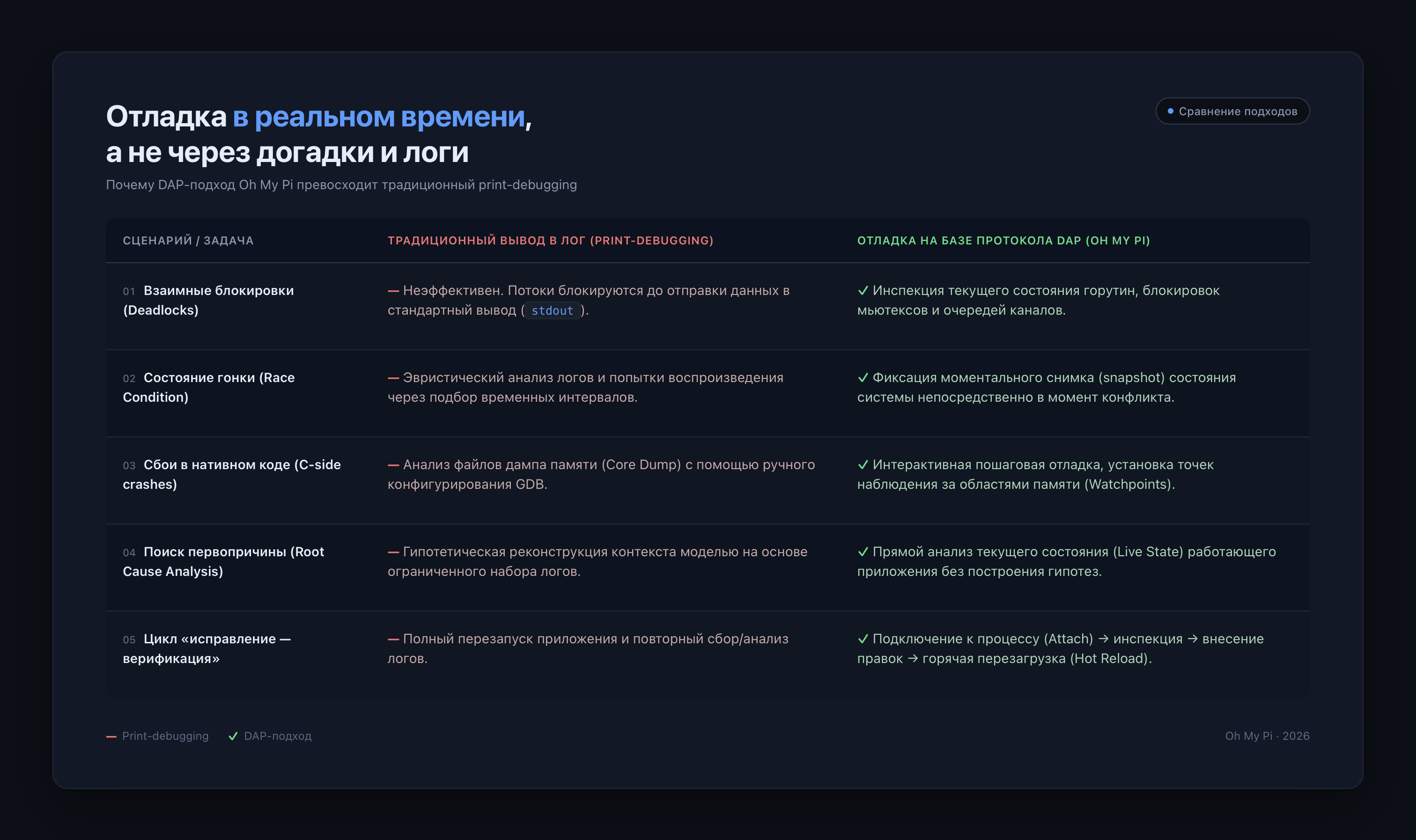
Вместо бесконечной расстановки отладочных принтов OMP сам управляет сессией отладки через debugpy или Go dlv. Он расставляет точки останова (breakpoints), исследует состояние памяти процесса прямо в момент возникновения ошибки, показывает содержимое переменных и реальную последовательность вызовов. В результате получается эффективная отладка без лишнего мусора в коде.
3. Точечные изменения в коде (Hash line edits)
Claude Code и большинство привычных CLI-агентов реализуют функцию редактирования, передавая в модель старую и новую строки с изменениями.
В этой схеме модели приходится посимвольно воспроизводить каждый символ старой и новой строки (включая пробелы, знаки табуляции и переносы строк). Так как LLM не всегда стабильно отличает табуляцию от пробела, это может привести к синтаксической ошибке.
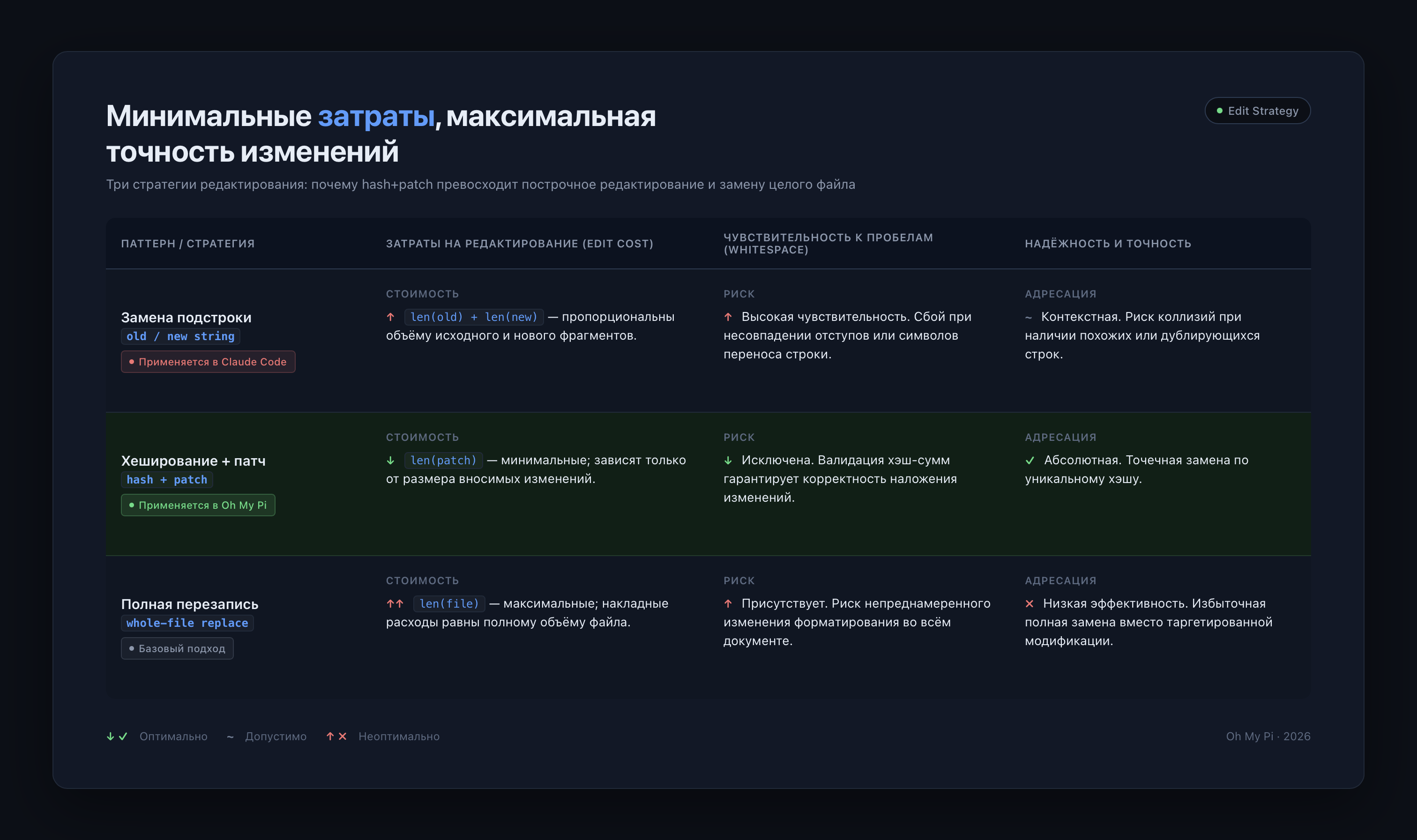
К тому же такой подход увеличивает расход токенов — на каждое мелкое изменение модель генерирует избыточный контекст, и одна и та же строка фигурирует в запросе повторно.
OMP при редактировании преобразует строки в хеши с помощью специальной функции. Модель, в свою очередь, возвращает только этот хеш и патч, а не целые строки «было» / «стало». Преимущество в том, что хеш уже содержит точное состояние строки: исключаются проблемы с форматированием, снижаются избыточные затраты токенов (передается только patch вместо всей строки), а также повышается точность — невозможно случайно отредактировать похожую строку в другом месте.
| Параметр | Стандартный подход (Claude Code) | Метод OMP (Hash line edits) |
|---|---|---|
| Что передается в модель | Строки целиком («было» и «стало») | Хеш строки + патч |
| Риск синтаксических ошибок | Высокий (из-за путаницы с табами и пробелами) | Полностью исключен |
| Объем генерации токенов | Избыточный (из-за дублирования контекста) | Снижен примерно на 60% |
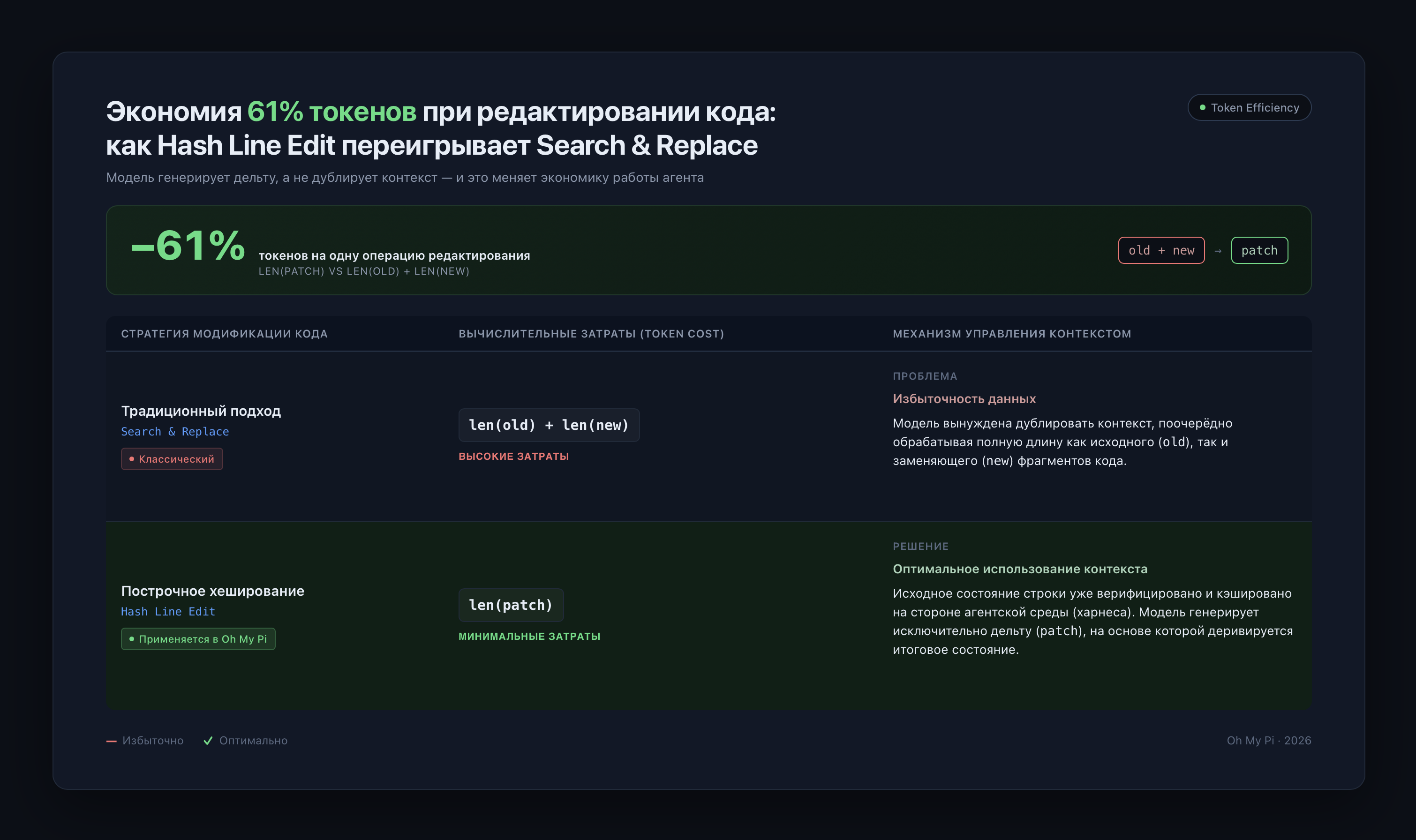
При сотнях мелких правок эта функция бережет значительную часть бюджета на API.
4. Мультимодельная архитектура (Model-Agnostic Harness)
Это подход, при котором разные модели распределяются по типам задач внутри одной сессии. OMP автоматически маршрутизирует задачи к подходящим нейросетям:
- Основная модель: пишет логику и решает общие архитектурные задачи.
- Vision-модель: распознает и анализирует UI-скриншоты.
- Специализированная модель: отвечает за генерацию UI и верстку.
- Легкая модель: используется для создания коммитов в Git или написания простых тестов.
Это позволяет улучшить качество на специфических задачах и оптимизировать затраты: для простых операций применяются недорогие модели, а для тяжелых — более мощные.
У агента также есть дополнительные возможности:
- Использование headless-браузера Chrome вместо стандартных команд
curlилиfetch. - Встроенный инструмент для код-ревью.
- Поддержка изолированных субагентов.
- Нативное чтение PDF-файлов.
- Собственная подсистема памяти.
- Совместимость с плагинами агента Pi.
Эволюция в сторону автономности
Разумеется, OMP — это не универсальное решение, которое напишет приложение вместо вас. Но этот проект наглядно иллюстрирует эволюцию архитектуры ИИ-агентов: слой между разработчиком и LLM качественно усложняется.
Базовые операции обрастают серьезными технологиями: статическим анализом через LSP и отладкой в рантайме через DAP. Агент начинает понимать архитектуру вашего приложения, а не просто перебирать строчки текста.
Сейчас мы говорим об автоматизации внутри одной сессии — когда вы сами контролируете процесс. Но индустрия уже движется к полной автономности. Проекты вроде SWE-agent из Принстона или концепты фабрик разработки вроде MetaGPT способны часами выполнять задачи, запускать тесты, анализировать логи и проводить отладку без вашего участия. Но это уже совсем другая история.